Don't Use Too Many Master Servers
OpenLDAP Clusters are frequently set up with too many servers functioning as "Master" servers. Over use of multi-master replication (MMR) hurts performance, capacity, and dependability.

Updated at July 27th, 2024
Table of Contents
Date: 05-20-2022
Multi-Master Replication (MMR)
MMR is a critical component in deploying highly available OpenLDAP services. MMR works for clusters containing many servers acting as "masters", taking updates from client applications. Symas tests 4-way and 6-way MMR clusters routinely.
That doesn't make use of that many masters for production a good thing. It works. But at a cost. And for no apparent benefit.
To discuss why this is true, let's construct an imaginary cluster with servers A, B, and C. We'll set up A as a master (to take all of the "writes") and make B and C replicas (replication consumers). Naturally, we add the chaining overlay to B and C as well as the syncrepl overlay to set up replication from A. "chaining" sends all updates received on B or C to A for processing. All writes are done to A and replicated to B and C. A load balancer would spread queries across all three servers.
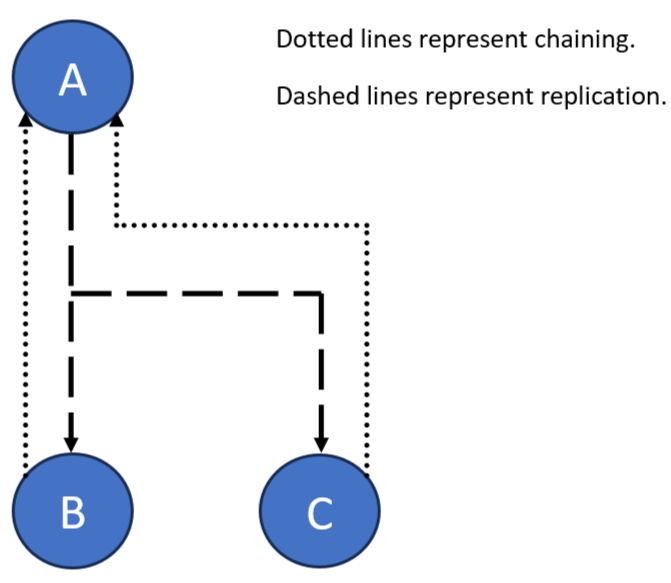
“chaining” is forwarding. The replica does nothing but send the request on to the master. A receives the forwarded write and processes it as if it was originally directed to A.
With "syncrepl" B and C request replication updates, typically in long running queries (refreshAndPersist queries). Any change to the database, done on a, results in "syncrepl" update messages to B and C. Each of the replicas get, in effect, the same update request done on A. They then process them and update their "syncrepl" "cookies" (contextCSNs).
So, we add an entry to A. That same entry is added to B and C. Three updates are done. Every one of the updates is identical. The replication controls are also updated. As are all relevant indexes we set up. One obvious conclusion is that the "write load" is the same on all the servers in the cluster. Another observation is that this is the minimum amount of replication traffic we can expect.
But High Availability?
Right. The reliability of this cluster isn't great. No matter what cause, if A is down, the cluster has no ability to handle updates! Bad! OBVIOUSLY we need to go MMR and add at least one more master. But do we add another server?
Maybe but, unless the query load is putting pressure on the cluster, probably not. We would make B (arbitrarily) a master server. Our cluster now looks like:
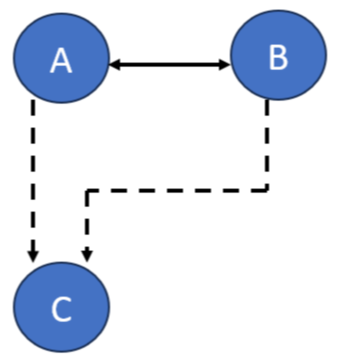
First, let's assume that ALL writes are still going to A. Some kind of "keep-alive" arrangement should be put in place so writes are redirected to B if A is not available. No real change is made to the load balancing of the queries.
The big change here is that C is set up to automatically request replication updates from BOTH A and B. We have to do that so failover is automatic. It's not a problem, both update notifications don't get processed. Only one. syncrepl recognizes when the second comes in it is not needed.
But the notification comes in. It is a "small transaction". Almost insignificant. But noted.
Optimal MMR
The two-way MMR in that last diagram is what Symas considers optimal. Adding a third, say C, actually adds more replication notification events, in total. The performance impact isn't huge but it's also non-productive. The only way we recommend it is to configure C to be able to become a master with a few dynamic configuration changes. Then a couple of scripts can be on the shelf to reconfigure replication, on the fly, if the master that is unavailable is going to be offline for a while. And a couple of scripts that can put things back to normal, later. The diagram doesn't change, only configuration settings.
But Write Speading For …
NO.
It's that simple.
No matter the clever looking/sounding topology, every server gets a write every time the LDAP database is changed. Spreading incoming writes just means that there is increased replication traffic. The "one write server" approaches minimizes unnecessary replication traffic and all the servers see the same update load.
ALL!!
So there is not update performance improvement. The extra replication traffic generated actually loads things down. That can't be good. Replication performance is only as good as the last replica to be updated. Excess traffic can't help that.
Seriously
When you think this all through, it is obvious that MMR is a very good thing. Taken beyond optimal levels, it becomes excess load and complexity, not good.
There is an approach that reduces the replication notification traffic on master servers. They put a layer of servers in between the masters and large numbers of replicas (consumers). Symas calls them “Hubs.” They replicate from the masters but they are replication producers (like masters) for the replicas. The slight net increase in replication events is counterbalanced by reduced load on each of the true master servers which can get bogged down responding to the replication queries of many replicas.
Disclaimer
None of this says you can't or even shouldn't go right ahead and set up MMR with several master servers taking updates. Configuration, over all, is more complex. Your mileage may vary. Symas is NOT SAYING MMR DOESN'T SCALE. We're saying scaling in that way doesn't deliver the performance or reliability one might imagine. 6-way MMR works. We tested it. The customers with complex MMR topologies that come to us with performance and fragility issues find that simplification makes things better. So that's our recommendation.